Nach Abschluss verschiedener Projekte wurde uns bei Polydocs klar, dass die Verarbeitung von Dokumenten allgegenwärtig ist – von Unternehmen bis zu Nichtregierungsorganisationen, von kleinen Betrieben bis zu Großkonzernen – es gibt immer ein PDF, das digitalisiert werden muss!
Die Verarbeitung von Dokumenten ist demnach also nicht nur schwierig, sondern vielleicht auch dringend notwendig.
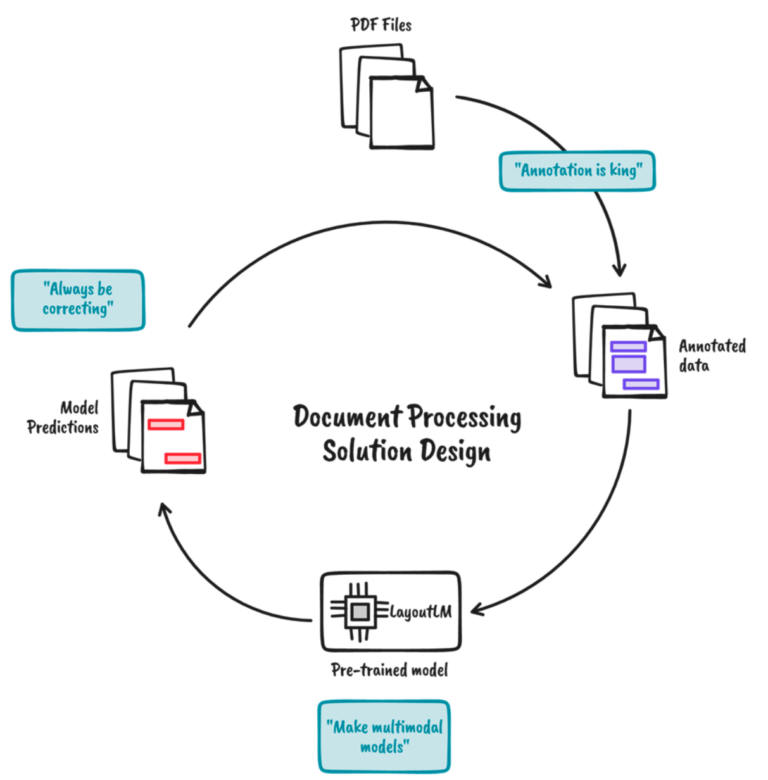
In diesem Blogbeitrag wird ein Rahmen für die Entwicklung von Dokumentenverarbeitungslösungen beschrieben und woran wir für DocBits Version 2.0 arbeiten.
in weiterer Grund, warum die Verarbeitung von Dokumenten eine so attraktive Herausforderung darstellt, liegt darin, dass sie von Natur aus multimodal ist – textliche und visuelle Informationen stehen ohne weiteres zur Verfügung. Jedoch neigen grobe Lösungen für die Dokumentenverarbeitung leider dazu, nur eins der beiden Modelle zu nutzen:
Bildzentrierte Ansätze beinhalten eine Menge komplexer Geschäftsregeln rund um Begrenzungsrahmen und Textplatzierung, um die erforderlichen Informationen zu erhalten. Sie verlassen sich meist auf Vorlagen, die nicht skalierbar sind. Textzentrierte Ansätze basieren auf NLP-Pipelines für OCR-erfasste Texte. Wobei Textblöcke jedoch nicht mit der Domäne kompatibel sind, auf der diese Modelle ursprünglich trainiert wurden, was zu einer suboptimalen Leistung führt.
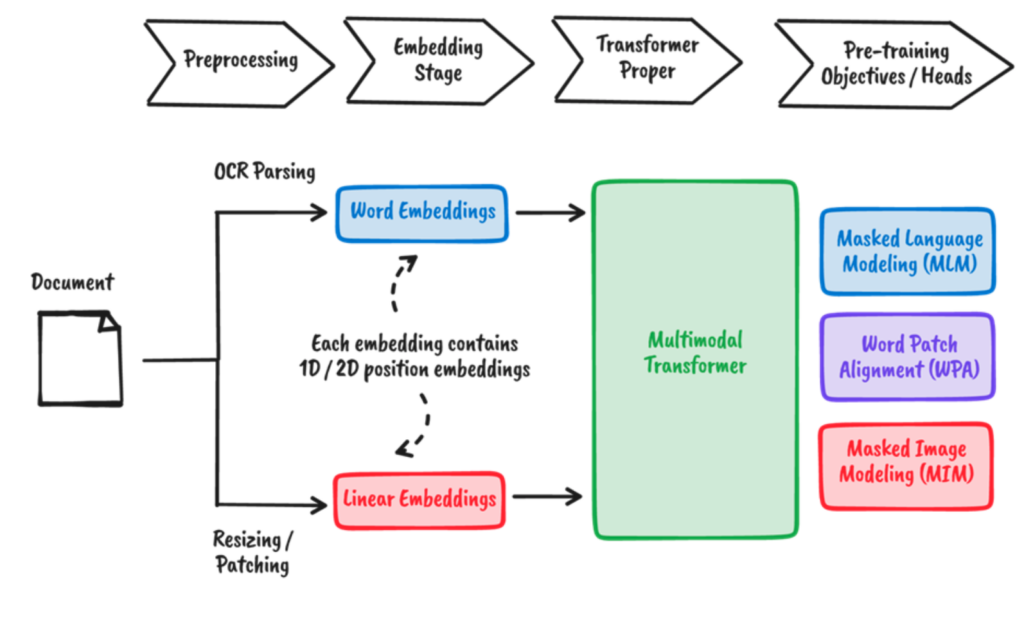
Glücklicherweise können multimodale Modelle wie DocBits aus textlichen und visuellen Informationen lernen. Für ein bestimmtes Dokument werden nicht nur das Wort und das Bild selbst, sondern auch ihre Positionen eingebettet. Die Interaktionen zwischen ihnen wird dann mit Hilfe mehrerer Vortrainingsziele erlernt.
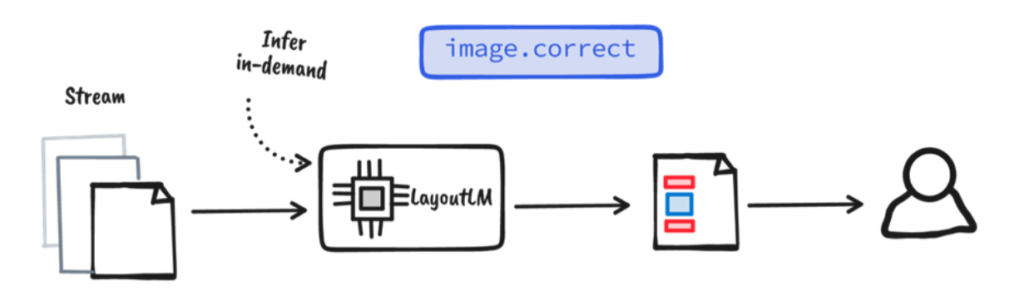
Wir sind nach wie vor der Meinung, dass man selbst bei einem noch so leistungsfähigen Dokumentenverarbeitungssystem menschliches Wissen und menschliche Erfahrung zur Korrektur und Bewertung einbeziehen muss. Human-in-the-loop kann als Endkontrolle für die Ausgabe eines Modells dienen. Wir können die korrigierten Anmerkungen wiederverwenden, um das Modell weiter zu verfeinern und so den Kreislauf zu schließen.